
Natural Language Analytics: The End of Traditional BI?
For decades, business intelligence has lived behind a wall. If you wanted answers from your data, you needed to speak its language: SQL, DAX, or the arcane syntax of a specific BI tool. You had to know where the data lived, how the tables joined, and which filters to apply. For the average business user, this wasn't an option. The result? A never-ending queue of requests to overworked data teams. But a fundamental shift is underway. Natural Language Analytics (NLA)—the ability to ask questions in plain English and get instant, visual answers—is tearing down that wall.
This isn't about making BI tools slightly easier to use. It's about reimagining the entire experience of data analysis. It's about moving from a world where data is a resource you have to request, to one where it's a partner you can converse with. In this blog, we'll explore how this technology works, whether it spells the end for traditional BI, and what it means for your Power BI projects and your organization's data culture.
The Problem with "Traditional" Business Intelligence
Traditional BI is built on a model of Production and consumption. A specialized team of analysts and developers gathers requirements, models the data, and builds dashboards. Business users then consume these dashboards. This model has served us well, but it has critical limitations .
First, it's slow. Every new question, every change in strategy, or every unexpected trend requires a request to the data team. This creates a bottleneck. What should be a quick question—"Why did sales drop in the Northeast last week?"—can become a ticket that takes days or weeks to resolve.
Second, it's inflexible. Dashboards are static. They are designed to answer a predetermined set of questions. If a user wants to explore a tangent or investigate an anomaly that isn't covered by the existing visuals, they are stuck. They either work with what they have or wait for a new dashboard to be built.
Third, it has a high barrier to entry. For a business user to truly self-serve, they need to understand data models, row-level security, and often a query language. Most business users lack this technical background, so the power of their data remains locked away, accessible only through an intermediary .
These challenges create a significant opportunity cost. According to industry research, over 60% of business leaders believe traditional BI tools are too slow to keep up with the pace of modern business . Natural Language Analytics is emerging as the solution to this problem .
How Natural Language Analytics Works (And Why It's Different)
The magic of NLA is powered by Natural Language Processing (NLP), a branch of AI that enables computers to understand and interpret human language. Modern NLA tools, however, go far beyond simple keyword matching.
Here’s a simplified breakdown of the process:
You Ask a Question in Plain English:
You type a question like, "What were our top 5 products by revenue last quarter?" .The AI Interprets Your Intent:
The AI's NLP engine parses your sentence to understand its intent and extract key entities. It identifies that "top 5 products" means you want a ranking, "revenue" is the metric, and "last quarter" defines the time period.It Generates a Structured Query:
The AI translates your plain-English question into the correct structured query language for your database, such as SQL or DAX. This is a crucial step. The most advanced tools don't just guess; they are schema-aware. This means they are connected to your actual database and know the real names of your tables and columns, so they generate a query that will actually work .It Executes the Query and Visualizes the Result:
The generated query is run against your live data, respecting all your existing security rules. The AI then presents the results in the most appropriate format—a chart, a table, or a narrative summary—making the insight instantly understandable .
The New Engines: From Q&A to Copilot
If you're a Power BI user, you might be familiar with the classic Q&A feature. It was an early example of this concept, allowing users to ask questions and get a single visual in return. However, this was an older technology with limitations. Microsoft has announced that the classic Q&A feature will be deprecated in December 2026 .
The future of Natural Language in Power BI is Copilot. Copilot represents a massive leap forward. Instead of the old rule-based engine, Copilot uses a powerful Large Language Model (LLM) combined with Retrieval-Augmented Generation (RAG) . This is a critical difference:
LLM (Large Language Model): This gives Copilot its incredible language understanding, allowing it to handle complex, multi-clause, and ambiguous questions like a human would.
RAG (Retrieval-Augmented Generation): This ensures Copilot's answers are grounded in your governed data. It doesn't just make things up. It retrieves the correct context from your semantic model to build its response. This prevents AI "hallucinations" and maintains data integrity .
This means Copilot can do more than just answer a single question. It can generate entire report pages, write DAX measures for you, create executive summaries, and maintain a conversational context, allowing you to drill down and explore insights in a much more natural way .
AI-Generated SQL and Dashboards: The New Reality
Natural Language Analytics is unleashing two powerful superpowers for business users:
1. AI-Generated SQL: No More Waiting for Queries
One of the biggest barriers to self-service data is the need to write SQL. NLA tools are eliminating this bottleneck. Tools like Nova AI and Snowflake Cortex are prime examples .
They allow anyone to simply ask a business question and, behind the scenes, generate the correct, validated SQL code. This isn't just about speed; it's about access. A sales manager can now investigate a regional trend without having to interrupt a data analyst. For power users, these tools can also act as an accelerator. They can draft a complex query for you, which you can then review, modify, and refine. It's like having a junior data analyst on hand at all times .
2. AI-Generated Dashboards: From Prompt to Report in Minutes
The ability to ask a question is powerful, but sometimes you need a full dashboard to monitor a specific process or KPI. AI is making this process remarkably simple.
Instead of spending days manually selecting data, designing visuals, and laying out a report, you can now generate a complete dashboard from a single prompt. For instance, a sales manager could type, "Create a sales performance dashboard showing revenue by region, top customers, and closed deals by rep for the last quarter," and the AI will build it in minutes .
Tools like Secoda and Knowi are pioneering this space, allowing users to instantly create a dashboard of charts, tables, and metrics . The best part is that these dashboards are not black boxes. They are transparent, allowing users to see the underlying SQL, edit it, and trust that the data is governed and secure. This democratizes creation, not just consumption.
The Burning Question: Is This the End of Traditional BI?
This is the million-dollar question. The short answer is: No, but it is the end of traditional BI as we know it.
Natural Language Analytics is not a complete replacement for traditional BI. Instead, it's a powerful complement that excels in different scenarios. The two approaches can be thought of as serving different needs. Natural Language Analytics shines when it comes to temporary, ad-hoc, and exploratory analysis . It is the tool a user turns to when they have a specific question that isn't answered by their standard dashboard. As such, it's less of an "end" and more of a "front door." It is a new, conversational interface that sits on top of your governed data.
Many leading data platforms are now merging these concepts. You can start with a natural language question, get your answer, and then easily pin that visual to a traditional dashboard for future monitoring. This hybrid model is the future of BI .
The Critical Pillar: Governance and Security
With the power of AI comes great responsibility. When anyone can ask any question, how do you ensure they only see what they are supposed to see? This is the critical challenge, and the most successful NLA implementations have tackled it head-on.
Data Security at the Core
Any enterprise-grade NLA tool must be designed with security in mind. The AI must not be a "super-user" that can bypass data restrictions. Instead, it must operate within the same security context as the user .
This means Row-Level Security (RLS) is paramount. If a sales rep can only see data for their own region in a traditional dashboard, the AI must enforce the exact same rule. A governed AI agent does this by design. It executes all generated queries within the user's active RLS context. It doesn't filter the data "after the fact." It never operates outside the user's allowed data slice, preventing any accidental or malicious data leakage .
How Security is Maintained
Platforms like PowerBI Portal's AI agent and Protegrity's Text to Analytics show how governance can be implemented effectively .
Semantic Models: The AI's understanding is grounded in a semantic model, which is a governed layer that defines business terms and rules. When you ask about "revenue," the semantic model ensures the correct calculation (e.g., net revenue vs. gross revenue) is always used, providing consistent and accurate answers .
Enterprise-Grade Platforms: Tools like Snowflake Cortex provide native AI capabilities that run entirely within the secure compute plane of your data warehouse. Your sensitive data never leaves the environment, eliminating the risk of connecting to an external LLM API .
Real-World Use Cases: Who Benefits?
The promise of Natural Language Analytics is already a reality, transforming how teams work across organizations .
Sales & Marketing: A sales manager can ask, "How are our subscription renewals trending this year compared to last year?" and get an instant answer with a chart. Marketing teams can analyze campaign ROI in real-time, reallocating budget to the best-performing channels mid-campaign .
Fraud Detection & Risk: Risk and compliance teams can ask timely questions about transaction anomalies and operational patterns, speeding up investigations without waiting for manual reports .
Supply Chain & Operations: Supply chain managers can assess vendor performance, inventory movement, and delivery timing on demand, identifying bottlenecks and inefficiencies immediately .
General Business Users: Perhaps the most significant impact is on any business user without SQL knowledge. The ability to "talk to data, not through tickets" fundamentally changes how they make decisions . A user can explore data iteratively, asking follow-up questions like, "Why did it drop?" or "Is this happening everywhere?" . This conversational exploration leads to richer insights and a deeper understanding of the business.
Conclusion: The Future of BI is a Conversation
Natural Language Analytics is not just a feature; it is a paradigm shift for the entire business intelligence industry. It finally delivers on the long-standing promise of data democratization, putting the power of analysis directly into the hands of the people who need it most.
The era of waiting in line for a report is ending. The future is one where data is a collaborative partner, responding to our questions in real-time and empowering us to make faster, more intelligent decisions. For your Power BI projects, this means exciting times ahead. The transition from the classic Q&A to the powerful Copilot is a clear signal of where the industry is heading: towards a more intuitive, conversational, and accessible data world.
This is the end of traditional BI's monopoly. The beginning of a new era of insight.
Intelligent Lakehouse: The Future of Data & AI
In today’s data-driven era, acquiring the right data, ensuring quality, and governing it effectively are essential for organizational success. Failure to do so can mean losing significant business opportunities. This article demonstrates how the Lakehouse architecture enables organizations to harness data strategically and unlock its true value.
This Article talks about “Intelligent Lakehouse: The Future of Data & AI”. We will highlight different components of the diagram in the Article below:

Internal Applications: Enterprise has its own set of applications (based on business Domain), from Web applications, Databases, ERP, CRM, mobile apps, etc.
External Applications: In many cases, enterprises need not manage every application in-house. Required functionalities can be acquired externally, with the complete ecosystem supported and maintained by third-party vendors.
Integration Layer: Bringing data from Internal or External Applications falls in the purview of the Integration Layer. This data will flow in the form of Files, API, or streaming.
Lakehouse: Stores all types of data (structured, semi-structured, unstructured, streaming) like a data lake. We can create a raw, model, and aggregated layer out of it.
Data Quality: High-quality data is a critical dimension of any data-driven system. Incomplete or inconsistent data can lead to misleading insights. Therefore, it is essential to build or adopt a robust data quality framework to ensure accuracy and trust in analytics.
Data Governance: Data Governance is the framework of policies, processes, roles, standards, and technologies that ensures an organization’s data is accurate, consistent, secure, and used responsibly.
Data Security: Data should be secure from misuse, threats, and unauthorized access.
Semantic Layer: A Semantic Layer is a business-friendly abstraction layer that sits between raw data sources and end-user tools (BI dashboards, AI models, applications).
Analytics: From the aggregate layer, we can expose data to reporting tools such as Power BI, Tableau, Looker, etc.
Customer Data Platform: A Customer Data Platform (CDP) is a centralized software system that collects, unifies, and manages customer data from multiple sources to create a single, consistent, and comprehensive customer profile.
Advance Analytics: We can create forecasting reports using the Machine learning capabilities. Thease are a wide range of reports such as Inventory forecasting, sales forecasting, customer churn, etc.
Summary:
A well-designed Lakehouse unlocks the true potential of enterprise data, delivering actionable insights that drive new initiatives and accelerate revenue growth. By unifying structured and unstructured data under a single architecture, it eliminates silos and ensures faster access to trusted information. This modern approach not only reduces complexity and cost but also empowers business leaders to innovate with confidence, improve customer experiences, and make data-driven decisions at scale. Ultimately, the Lakehouse becomes the foundation for sustainable growth and competitive advantage in the digital era.
Security Layers for Enterprise LLM-Based Applications

In the era of Large language model (LLM) availability and their uses, enterprise has to be careful to design their applications, considering external threat and attacks. We have been discussing some of the best practices to enable security for LLM-based applications at the Enterprise level. There are a bunch of tools in the market; however, our article focuses more on the method instead of Tools, as we have proposed the following layers of security, which include traditional methods and new, evolving methods. More details are given below:
API Gateway:
User-initiated traffic passes through the API gateway. We have to implement authorization and authentication. Additionally, we can leverage the API gateway for the following services:
1. Auth & RBAC
2. Rate Limiting
3. WAF & Bot Protection
4. TLS + GW level Logging
AI Gateway:
The next component is the AI Gateway, which can scan both incoming and outgoing traffic. It can perform the following things:
1. PII/PHI Protection
2. Prompt Security
3. Output Guardrails
4. Audit & Compliance
Application or Code level:
For a genAI application, we can build an additional framework, which can add functionality to sanitize incoming text. This new table will contain the metadata for sensitive information, prompts, jailbreak text, and other elements used for validation. Text will be sensitized before sending to LLM. Similarly, outgoing text will also be sanitized at the application level.
Database:
The database is an important component; we can't expose enterprise data to everyone. Here comes role based, ABAC, column/ row level security, other than encrypting data.
Summary:
leveraging API/AI Gateway, code level data sanitization and enabling data security and governance principal, we can make safe and better AI application.
Event-Driven / Queue-Based Architecture in Retail
Introduction
Retail organizations today operate in highly dynamic environments where real-time responsiveness is critical. Whether it’s inventory updates, customer orders, fraud detection, or personalized marketing, the ability to process and respond to events as they occur can directly impact revenue and customer satisfaction. This is where Event-Driven Architecture (EDA) and Queue-Based Systems come into play.
What is Event-Driven Architecture?
Event-Driven Architecture is a design paradigm where events (such as “order placed,” “item shipped,”) act as the primary communication mechanism between services. Instead of polling or requesting data continuously, services subscribe to and react to events as they happen.
In a retail context:
A customer order generates an event.
The inventory service consumes the event and reduces stock levels.
The billing service processes payment.
The shipping service schedules delivery.
The marketing service may trigger loyalty rewards or personalized offers.
Role of Queues in Retail
While events are asynchronous, queues ensure reliability and order:
Message Queues (e.g., Kafka, RabbitMQ, AWS SQS, Azure Service Bus) store events until consumers process them.
This prevents data loss during traffic spikes (e.g., Black Friday sales).
Multiple consumers can subscribe, ensuring parallel processing across retail functions.
Benefits for Retail Companies
Scalability – Handle millions of orders, product updates, and customer interactions in peak shopping times without downtime.
Resilience – If one microservice (e.g., shipping) is down, events remain in the queue until it recovers.
Real-Time Experience – Customers see real-time stock availability and order confirmations.
Decoupling – Services like payment, inventory, marketing, and logistics evolve independently.
Data-Driven Insights – Streaming data pipelines provide customer behavior analytics in real-time.
High-Level Architecture Diagram
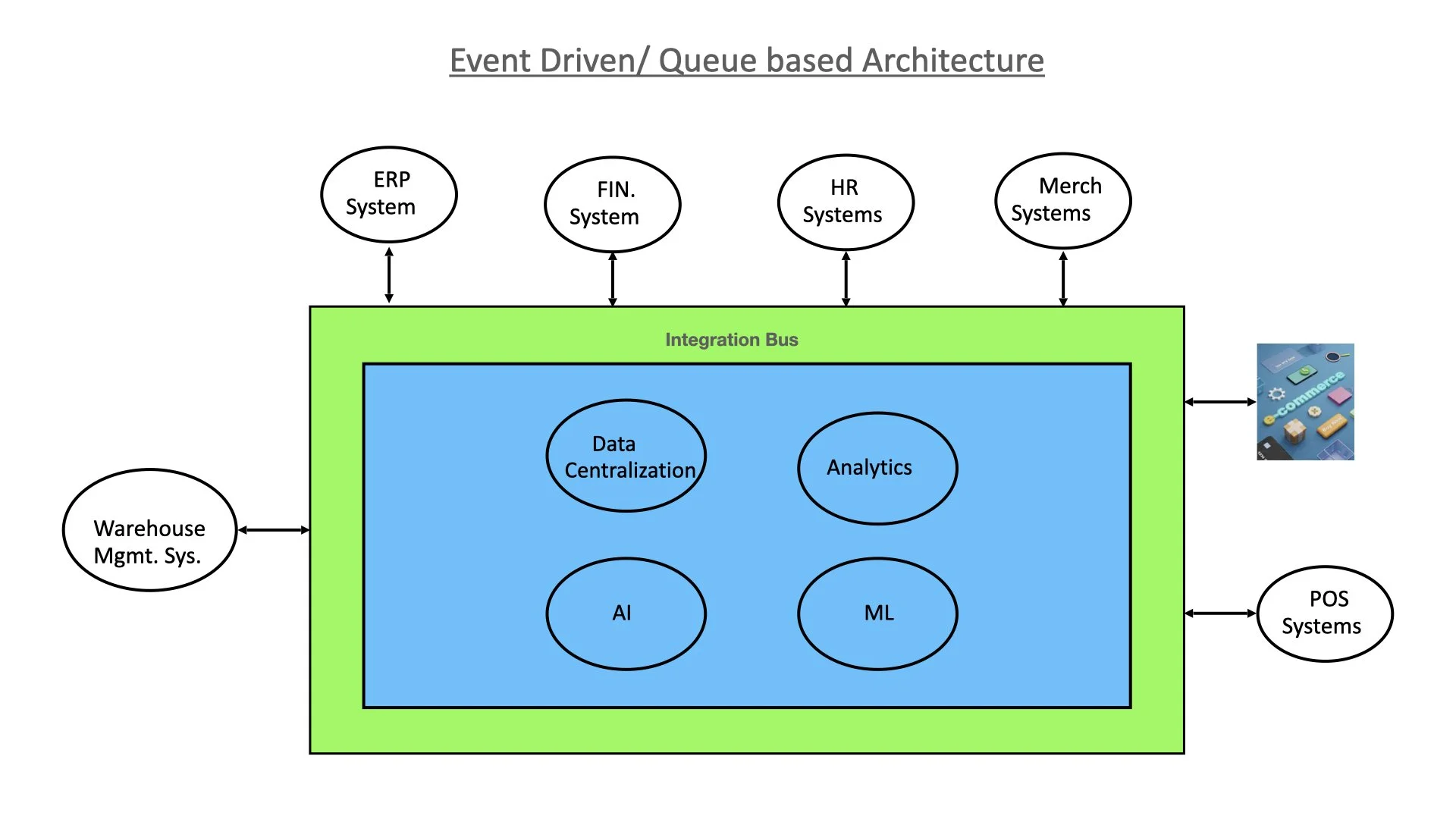
Conclusion
Event-Driven and Queue-Based Architecture enables modern retail companies to transform from batch-driven, siloed systems into real-time, scalable, and customer-centric ecosystems. With careful implementation, retailers gain agility to react instantly to customer needs, optimize operations, and innovate faster in a highly competitive market.
Agent2Agent (A2A) Protocol
Introduction:
The rapid advancement of AI has ushered in a new era of intelligent systems, where autonomous agents are no longer just experimental but are being deployed at scale across industries. As these agents grow in complexity and number, seamless communication between them becomes essential. To address this, Google introduced the Agent2Agent (A2A) Protocol—a structured approach designed to facilitate efficient, reliable, and standardized communication among AI agents.
This protocol emerges as part of the broader evolution in AI infrastructure, where new processes and frameworks are continuously being developed to meet real-world demands. A2A enables agents to collaborate, delegate tasks, and share context—paving the way for more advanced, multi-agent systems capable of solving complex problems in dynamic environments.
Approach:

Fig.1. A2A Flow
As illustrated in the diagram, the user initiates a request through an application. The application forwards this request to an intelligent agent (Agent 1). During processing, Agent 1 identifies the need for additional context or data that it does not possess. Instead of redundantly fetching or recalculating the information, Agent 1 communicates with another agent (Agent 2) that already holds the required knowledge. By leveraging Agent 2’s capabilities via the Agent2Agent (A2A) Protocol, Agent 1 can quickly access the necessary data, respond more efficiently, and significantly reduce processing time and resource consumption.
Benefits:
Discovery:
Agents can dynamically identify and locate other agents with the necessary capabilities or data. This enables more flexible and scalable multi-agent ecosystems.
Negotiation:
Agents can communicate to reach agreements on how to share resources or divide tasks. This promotes efficient and autonomous decision-making in distributed systems.
Task Management:
A2A allows agents to delegate, accept, or coordinate tasks based on their availability and specialization. This ensures optimal task distribution and load balancing.
Collaboration:
Agents can work together by exchanging context, insights, and progress updates in real-time. This leads to more intelligent, cooperative behavior across complex workflows.
References:
https://developers.googleblog.com/en/a2a-a-new-era-of-agent-interoperability/
https://www.microsoft.com/en-us/microsoft-cloud/blog/2025/05/07/empowering-multi-agent-apps-with-the-open-agent2agent-a2a-protocol/
Part 1: Exploring Model Context Protocol (MCP) in Data and AI
Introduction:
AI is not new to us; over time, enormous studies and research have been conducted in this area. Whether it is machine learning, Deep learning, expert systems, Robotics, Image, or Natural language processing, all these AI subfields went through significant changes; however, December 2022 was a watershed moment for Deep learning. During this time, OpenAI [2] introduced the LLM model. Not only the industries, but even the common man has started using the LLM [1]. We have seen chatbots and other use cases floated around using LLM. LLMs are good for text summarization, but can’t store data and talk to applications. Let's say LLM has written an email, but it does not know whether this email has to be sent through Gmail or Outlook. Industry was missing a kind of standard. At the end of 2024, anthropic Team [3][4] has launched a defined standard on how LLM can be leveraged within the industry or outside of the industry (how tools and systems can feed structured data into LLM). It has given more opportunities to use LLM in subsequent use cases and a better method of interaction with applications.
Details Discussion:
As per the diagram, the user query is received by the application or program, which will have capabilities to connect with different systems such as databases, web applications, and so on. As per Fig.1, the middle part will resolve the context and will send this to the LLM model for the subsequent task, and will get a response from the LLM. Based on the logic, in case a program or app connects to the required applications.
Experiment:
from mcp.server import MCPServer
from pymongo import MongoClient
class MongoDBMCPServer(MCPServer):
def __init__(self, mongo_uri):
super().__init__()
self.client = MongoClient(mongo_uri)
self.db = self.client.your_database_name
# Registering a tool to find documents
self.register_tool("find_documents", self._find_documents)
def _find_documents(self, collection_name, query):
collection = self.db[collection_name]
results = list(collection.find(query))
return {"status": "success", "data": results}
# Example usage:
# server = MongoDBMCPServer("mongodb://localhost:27017/")
# server.run() # This would start the MCP server
server.operation({ …
});
server.operation({
name: “insertDocument”,
description: “Insert a document into a mongoDB collection”,
input: InsertDocumentSchema,
….
});
server.operation({ …
});
server.operation({ …
});
// Initialize the server
const.transport = new StdioServerTransport();
server.listen(transport)
There are numerous places where we can use MCP in Data and AI areas, a few examples are given below:
1. Getting a pipeline (e.g., ETL) job failure reason
2. Which dataset failed the quality check, and why?
3. Sales report execution
4. Sales forecasting
Summary:
Model context protocol has paved the way to acquire companies and build a variety of use cases using Large Language Model (LLM). It has simplified the work and increased productivity within the industry.
References:
[1]. https://en.wikipedia.org/w/index.php?title=Large_language_model&action=history, 0:24, 3 August 2025
[2]. https://en.wikipedia.org/wiki/OpenAI
[3]. https://blog.modelcontextprotocol.io/posts/welcome-to-mcp-blog/
[4]. https://modelcontextprotocol.io/overview
Revolutionizing Data-Driven Enterprises with Large Language Models (LLMs)
Introduction: The Data-First World We Live In
Explosion of Data from Modern Technologies
We live in an era where data isn’t just being generated — it’s erupting like a digital volcano. Web applications, mobile apps, social media, autonomous vehicles, smart cities, and IoT devices are spewing out torrents of information every second. Whether it’s a drone mapping a city, a fitness tracker recording steps, or an e-commerce app capturing clickstreams, the outcome is the same: enormous volumes of data, captured at breakneck speed and with varying structures.
What’s truly groundbreaking is not just the volume, but the velocity and variety. It’s no longer just structured data from databases but unstructured formats like videos, audio logs, emails, and sensor data. Healthcare systems, for instance, are flooded with MRI scans, patient records, prescriptions, and clinical trial results — all of which hold critical insights, if only we could tap into them quickly.
The Role of Enterprises in Extracting Value
Enterprises today are sitting on a goldmine of data. Yet, merely having access to data is no longer a competitive edge. The real differentiator is in extracting actionable insights — quickly and efficiently. Data analytics has traditionally required a well-oiled machine of data engineers, analysts, and domain experts. This machine, while effective, is time-consuming and expensive. The process of collecting, cleaning, and analyzing data can span weeks to months, depending on complexity.
Executives and decision-makers often find themselves waiting for dashboards or custom reports to make strategic decisions. And in today’s fast-paced world, delay equals lost opportunities. Businesses need answers in hours — not weeks.
The Promise of Large Language Models (LLMs)
This is where Large Language Models (LLMs) [1] enter the scene. Think of them as intelligent assistants trained on massive corpora of text and data, capable of understanding human language and context. But they’re not just glorified chatbots. LLMs can generate code, write SQL queries, summarize documents, and even conduct preliminary data science tasks — all through simple natural language commands.
The implications for enterprises are profound. With LLMs, the barriers to accessing and interpreting data crumble. Non-technical stakeholders can ask business questions in plain English and receive answers that previously required specialized teams to provide. The result? More people making data-driven decisions, faster turnaround times, and a significant boost in business agility.
Understanding LLMs and Their Business Relevance
What Are Large Language Models?
Large Language Models are AI systems trained to predict and generate human-like text. They’re built on transformer architecture, which allows them to analyze context across large bodies of text and produce coherent responses. The most famous examples include OpenAI’s GPT models, Google’s PaLM, and Meta’s LLaMA.
They are trained on diverse datasets — ranging from books, research papers, blogs, to programming documentation. This equips them with a generalized understanding of language, logic, code, and even reasoning. The best part? They can be fine-tuned to suit domain-specific needs — be it finance, healthcare, or manufacturing.
How LLMs Fit into Enterprise Data Strategy
Most enterprises have invested in a data ecosystem comprising databases, analytics platforms, business intelligence (BI) tools, and data lakes. But these systems are fragmented and require technical proficiency to extract insights.
LLMs can be integrated into this ecosystem to act as a bridge between humans and data. They can query data warehouses using natural language, explain data trends in plain terms, and automate repetitive reporting tasks. Think of it as embedding a highly skilled data analyst within every application — always available and infinitely scalable.
Efficiency Gains from LLMs
The key advantage of LLMs isn’t just intelligence — it’s speed. What used to take hours of SQL writing or data wrangling can now be accomplished with a sentence. A sales manager might say, “Show me the top 10 products by revenue in Q1 2024,” and get a detailed report instantly.
LLMs also reduce dependency on specialized roles for routine analysis, freeing up technical teams to focus on innovation rather than operational tasks. This doesn’t mean jobs are being replaced; rather, human potential is being reallocated to higher-value initiatives.
Use Case 1: LLMs for SQL Report Generation
The Traditional Workflow of Report Creation
In most organizations, report generation is a multi-step affair. It typically begins with a request from an executive or business stakeholder. This request travels through multiple teams — analysts to understand requirements, data engineers to build ETL pipelines, and BI developers to visualize the data. Depending on complexity, this process can stretch from a few days to several weeks.
Moreover, each change or follow-up request restarts the cycle. If the executive wants to slice the data by geography or adjust metrics, the entire pipeline may need tweaking. This dependency chain is inefficient, costly, and hinders agility.
Barriers Faced by Non-Technical Users
One major roadblock is language. Most executives don’t speak SQL or Python. And why should they? Their expertise lies in strategic thinking, not query optimization. Yet, in the traditional model, their insights are bottlenecked by their inability to “speak” to the data systems directly.
This creates a divide — those who can access data (technical teams), and those who need data to make decisions (business users). This misalignment often results in delayed insights, lost context, and missed opportunities.
How LLMs Simplify Report Generation
With LLMs, that divide is eliminated. These models can interpret natural language queries and convert them into SQL statements or even call APIs to fetch data. For instance, a simple prompt like “Show monthly sales trends for the North American region” is translated into a SQL query and run on a Snowflake or BigQuery backend.
But it’s not just about syntax translation. LLMs understand business context. They can infer what “sales trends” means, which tables to query, and how to group data over time. This makes them powerful allies in generating fast, reliable, and contextual reports.
Example: Sales Forecasting via Natural Language Prompting
Consider a scenario where a company needs a sales forecasting report for the next quarter. Traditionally, this involves gathering historical sales data, cleaning it, selecting a model, training it, and finally visualizing the output — a process that can take months.
With LLMs, a business user can simply ask, “Forecast next quarter’s sales using last year’s data and account for seasonality.” The LLM will fetch historical data, apply a time series model (like ARIMA or Prophet), and present predictions — sometimes even visualized.
This drastically reduces the time-to-insight, lowers costs, and empowers decision-makers with timely, actionable intelligence.
Summary: The Future of Enterprise Intelligence
As data continues to grow at exponential rates, the challenge for enterprises is no longer in acquiring it — but in making sense of it quickly and efficiently. Large Language Models (LLMs) are redefining how we interact with data by bridging the gap between natural language and technical data systems. Through practical use cases like automated SQL report generation and accelerated data science workflows, LLMs are enabling faster, democratized, and more accessible insights across organizations.
This doesn’t imply that human roles will vanish. Instead, these technologies enhance human capabilities, allowing technical teams to focus on strategic innovations while enabling non-technical users to self-serve their data needs. From reduced costs and shorter timelines to smarter, faster decision-making — LLMs are rapidly becoming a cornerstone in enterprise digital transformation.
Adopting LLMs isn’t about replacing the workforce; it’s about redefining how value is delivered across the organization. With tools like agents, LangChain, and prompt-based querying, businesses now have the opportunity to unlock the true potential of their data ecosystems, regardless of internal technical limitations.
Whether you’re an executive, data analyst, or part of an IT leadership team — it’s time to embrace LLMs as your strategic advantage in this data-driven era.
References
[1]https://medium.com/data-science-at-microsoft/how-large-language-models-work-91c362f5b78f
[2]https://medium.com/data-science/how-llms-will-democratize-exploratory-data-analysis-70e526e1cf1c
[3].https://stefanini.com/en/insights/articles/llm-data-assistants-will-improve-data-democratization